1. Elastic Search란? 검색 엔진? 분석 엔진?
Elastic Search에 대해서 지속적으로 포스팅을 남겨보려 합니다.
입문자도 알아들 수 있을 만큼 복습하고 정리할겸 최대한 자세히 포스팅을 하도록하겠습니다.
틀린 부분이라던지 고쳤으면 하는 부분이 있다면 댓글로 남겨주세요 (๑•̀ㅁ•́)ฅ✧!
엘라스틱 서치, ES, Elastic, Elastic Search 처음 접했을 땐 단순 nosql, big data엔진으로만 알았던 엘라스틱서치
많이 부족하지만 제가 배웠던 토대로 꼼꼼히 작성해보도록 하겠습니다.
우선 Elastic Searh란?
- 고가용성의 확장 가능한 오픈소스
- 검색엔진
- 분석엔진
- (no-sql 처럼 사용 가능)
Elastic Search가 무엇이냐 하면 크게 위와같은 4가지 특징으로 들 수 있을 것 같습니다.
사용 용도에 따라 다르겠지만 크게는 2가지 넓게 바라보면 3가지 정도로 쓰이는 것 같습니다.
+ 참고로 고가용성 (HA : High Availability)이란?
" 서버, 프로그램등의 정보시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 의미한다. "
라고 wikipedia에 나와있지만 쉽게말해서 프로그램이 정상적으로 고장안 나고 오래 운영(사용) 되는것이 고가용성이라고 이해하면 좋을 것 같습니다.
검색엔진으로 사용되는 Elastic Search
검색엔진으로 사용되는 ES(Elastic Search)를 알려면 먼저 Lucene(루씬)을 알아야합니다.
루씬 기반으로 개발 된 서비스이기에 Lucene과 ES 각각의 큰 특징들을 알아보겠습니다.
Lucene (루씬)
- Java 언어로 이뤄짐
- Apache 재단 검색엔진 상위 프로젝트
- Doug Cutting (하둡 창시자)에 의해 개발
- Apache 라이센스 배포
Elastic Search (엘라스틱 서치)
- Shay Banon이 Lucene기반으로 개발
- 똑같이 Java 언어로 이뤄짐
- Apache 2.0 라이센스 의거
- HTTP Web 인터페이스 지원
- Json 형태의 도큐먼트 지원
- 준 실시간 분산형 검색엔진
분석엔진으로 사용되는 Elastic Search
분석엔진으로 사용되는 ES를 사용하려면 몇가지 솔루션 추가로 분석 엔진으로 사용이 가능합니다.
이 몇가지 솔루션이 추가된 구조(스택)을 ELK라고 칭합니다.
로그 분석를 위해 다음과 같은 ELK(Elastic, LogStash, Kibana) 스택이 사용됩니다.
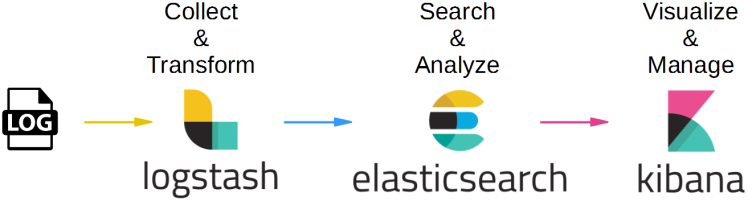
- Beats (비츠) = 로그를 Elastic나 LogStash로 전달
- 여러 (로그, 데이터)종류에 따라 각각의 Beats 존재
- 로그나 데이터 수집 용도
- Log Stash (로그 스태쉬) = 로그를 수집 파싱이나 필터링 기능 수행
- 때에 따라 데이터 수집 용도로 쓰일 수 있음
- 필터링 기능
- eg. 필터링 = 비정형화된 데이터들을 정형화 (=통일성 없는 데이터들을 통일성 있게)
- Elastic Search (엘라스틱 서치) = 검색, 분석을 할 수 있도록 Analyze를 거쳐 데이터 저장
- 정형화된 데이터 저장
- Kibana (키바나) = 저장(수집)된 ElasticSearch 데이터를 통계/집계해 시각화 제공
- 시각화 Tool
- 모니터링 가능한 대시보드 UI 제공
NO-SQL 처럼 사용가능 한 Elastic Search
다음 포스팅에 자세히 얘기할 예정인데 가볍게 말하자면
ES에는 저장되는 데이터 단위가 문서(doc)단위로 저장된다.
(cf. RDB로 말하면 한 행(row))
ES를 문서를 추가(indexing)할 때 id를 자동 or 수동으로 설정할수있는데
이 때 id를 수동으로 사용자가 지정할 경우 No-SQL처럼 사용할 수 있다라는 뜻이다.
하지만 Elastic Search에서 말하는 색인(indexing) 최적화를 위해선
id를 수동(PUT)으로 인덱싱하는것 보다 자동(POST)로 생성하는것을 권고 라고 합니다.
그래서 nosql용도로만 ES를 쓰기엔 아깝다는 의견이 있는데요.
이 부분에 대해선 제가 좀 더 공부해보고 포스팅하도록 하겠습니다(つ﹏<。)
cf. 수동으로 id를 넣어 인덱싱 할 경우
해당 id의 문서가 있는지 먼저 체크를 하기에 문서가 많아지면 많아 질 수록 부하가 커진다고 합니다.
이렇게 ES가 무엇인지
각 용도에 따라 어떠한 특징을 가지고있는지 가볍게 알아봤는데요.
ES는 크게 검색엔진과 분석엔진으로 사용되고 있다는 점 상기 시키며
다음번 2. Elastic Search 용어 정리 로 찾아뵙도록 하겠습니다.
감사합니다.
'Development - Search Engine > Elastic Search' 카테고리의 다른 글
| 3. Elastic Search 개념 정리 (0) | 2019.07.15 |
|---|---|
| 2. Elastic Search 용어 정리 (0) | 2019.07.15 |
